This section covers the Server-Side Cache and configurations available in the Server-Side Row Model.
As many of the configurations available in the Server-Side Row Model relate to the Server-Side Cache it is important to understand how the grid organises data obtained from the server into caches.
Server-Side Cache Copy Link
The grid arranges rows into blocks which are in turn stored in a cache as illustrated below:
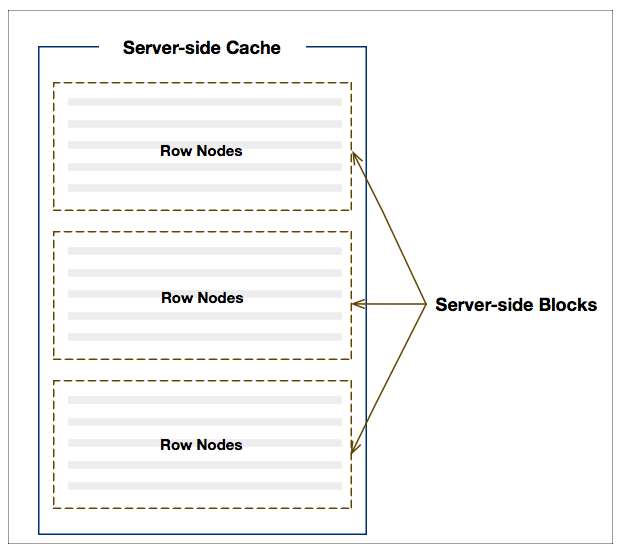
Fig 1. Server-side Cache
There is a cache containing the top-level rows (i.e. on the root node) and for each individual Row Grouping level. When the grid initialises, it will retrieve an initial number (as per configuration) of blocks containing rows, and as the user scrolls down more blocks will be loaded.
Several Configurations, such as cacheBlockSize and maxBlocksInCache, are expressed in terms of the Server-Side Cache.
The example below demonstrates some configurations. Note the following:
- The grid property
cacheBlockSize = 50. This sets the block size to 50, thus rows are read back 50 at a time. - The grid property
maxBlocksInCache = 2. This means the grid will keep two blocks in memory only. To see this in action, scroll past row 100 (which will require a third block to be loaded), then quickly scroll back to the start and you will observe the first block needs to be reloaded.
Block Loading Debounce Copy Link
It may be desirable to scroll through the entire dataset without the need for intermediate blocks to be loaded.
The example below shows how debouncing block loading can be achieved. Note the following:
The response from the server sets the
rowCountproperty so that the vertical scrollbars bounds are set such that the entire dataset can be scrolled through.blockLoadDebounceMillis = 1000- loading of blocks is delayed by1000ms. This allows for skipping over blocks when scrolling to advanced positions.The grid property
debug = true. This means the browser's dev console will show loading block details.
Providing Additional Data Copy Link
It is possible to supply extra data to the grid outside of the datasource lifecycle. This can be used to populate the grid with data before scrolling, provide hierarchical data, or provide additional blocks.
Applies row data to a server side store.
New rows will overwrite rows at the same index in the same way as if provided by a datasource success callback. |
The example below demonstrates that the grid can be populated with data outside of the datasource flow. Note the following:
- The first loading row never displays, as the first 100 rows are loaded by default
- 100 rows are provided by default, ignoring the
cacheBlockSizeproperty - The loading of these additional rows bypasses the
blockLoadDebounceMillisandmaxConcurrentDatasourceRequestsproperties.
Initial Scroll Position Copy Link
When using the server-side row model the initial scroll position of the grid can be set. This is achieved by calling api.ensureIndexVisible() after setting the data source to the grid.
It is important that the serverSideInitialRowCount property is set to a value that is greater than the sum of the row index provided to api.ensureIndexVisible() and the number of rows displayed in the grid's viewport.
This is demonstrated in the example below, note the following:
The
serverSideInitialRowCountproperty has been set to provide an initial length to the vertical scrollbars.After the datasource has been set
api.ensureIndexVisible(5000, 'top')is called, causing the grid to scroll down to row5000.
Providing Row IDs Copy Link
Some features of the server-side row model require Row IDs in order to be enabled or to enhance their behaviour, these features include Row Selection, Transactions and Refreshing Data.
The server-side row model requires unique Row IDs in order to identify rows after new data loads. For example, if a sort or filter is applied which results in new rows being loaded, the grid needs to be able to identify the previously known rows.
Row IDs are provided by the application using the getRowId() callback:
Provide a pure function that returns a string ID to uniquely identify a given row. This enables the grid to work optimally with data changes and updates. |
When implementing getRowId() you must ensure the rows have unique Row IDs across the entire data set. Using an ID that is provided in the data such as a database Primary Key is recommended.
Supplying Unique Group IDs Copy Link
When grouping there may not be an easy way to get unique Row IDs from the data for group levels. This is because a group row doesn't always correspond to one Row in the store.
To handle this scenario, the grid provides parentKeys and level properties in the GetRowIdParams supplied to getRowId().
These can be used to create unique group IDs as shown below:
const getRowId = useCallback(params => {
const parentKeysJoined = (params.parentKeys || []).join('-');
if (params.data.id != null) {
return parentKeysJoined + params.data.id;
}
const rowGroupCols = params.api.getRowGroupColumns();
const thisGroupCol = rowGroupCols[params.level];
return parentKeysJoined + params.data[thisGroupCol.getColDef().field];
}, []);
<AgGridReact getRowId={getRowId} /> Debug Info Copy Link
When using the server-side row model it can be helpful to gather the state of each block. This can be gathered by using api.getCacheBlockState() or alternatively you can enable debug: true in the grid properties to see this output logged to the console whenever blocks are loaded.
In the example below, note the following:
- The grid option
debug: truehas been enabled - When scrolling through the grid, block information is logged to the console
Next Up Copy Link
Continue to the next section to learn about SSRM Sorting.